챕터 04 선수지식: 변이와 진화에 들어가기 전 알아야 할 것
1. 4챕터는 무엇을 하려는 장인가요?
4챕터는 크게 두 가지 질문을 다룹니다.
첫째, 어떤 사람이나 생물의 DNA가 표준 유전체와 어디가 다른지 어떻게 찾을까요?
둘째, 그런 DNA 차이가 집단 안에서 시간이 지나며 어떻게 퍼지거나 사라질까요?
앞의 2장에서는 유전체와 변이의 종류를 배웠고, 3장에서는 NGS로 DNA 조각을 읽고 참조 유전체에 정렬하는 과정을 배웠습니다. 4장은 그 다음 단계입니다. 즉, “이제 DNA 조각들을 어느 위치에 붙였으니, 기준과 다른 부분을 실제로 찾아보자”는 장입니다.
4장에서 나오는 핵심 흐름은 다음과 같습니다.

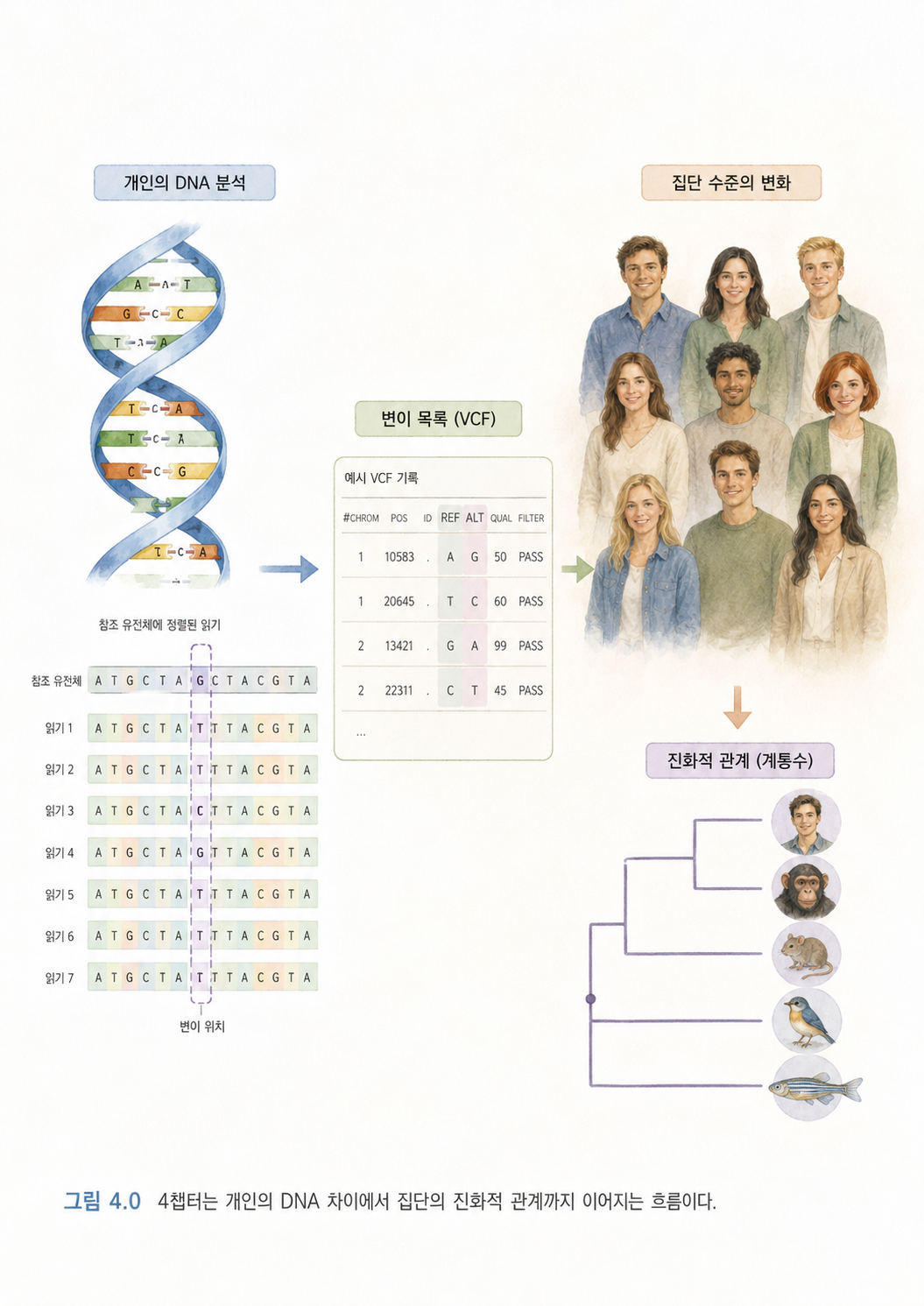
처음에는 변이 찾기, VCF, Phasing, Contamination 같은 분석 용어가 등장합니다. 뒤로 가면 하디-바인베르크 평형, 유전적 부동, 진화, 다중서열정렬, 계통수, 병원체 진화 추적, 고유전학 같은 집단유전학과 진화생물학 개념이 나옵니다.
따라서 4장을 읽기 전에는 다음 감각이 필요합니다.
DNA의 작은 차이는 개인의 특징을 만들 수 있고, 그 차이가 집단 안에서 세대를 거치며 비율이 바뀌면 진화라고 볼 수 있습니다.
2. 변이 찾기는 “틀린 글자 찾기”가 아니라 “기준과 다른 글자 찾기”입니다
변이 찾기(Variant Calling)를 처음 보면 “DNA에서 오류를 찾는 일”처럼 느껴질 수 있습니다. 하지만 변이는 꼭 나쁜 것도 아니고, 꼭 오류도 아닙니다. 변이는 단순히 기준이 되는 유전체와 다른 부분입니다.
예를 들어 표준 문장이 다음과 같다고 해보겠습니다.
나는 오늘 학교에 갑니다.
어떤 사람의 문장은 다음과 같을 수 있습니다.
나는 오늘 학원에 갑니다.
여기서 “학교”와 “학원”이 다릅니다. 그렇다고 “학원”이 무조건 틀린 말은 아닙니다. 그냥 기준 문장과 다른 것입니다. DNA 변이도 이와 비슷합니다. 표준 유전체에는 A가 있는데 어떤 사람에게는 G가 있을 수 있습니다. 이 차이가 질병과 관련될 수도 있고, 아무 영향이 없을 수도 있고, 아주 흔한 정상적 다양성일 수도 있습니다.
4장에서 말하는 변이 찾기는 대략 이런 일입니다.
- NGS 장비가 DNA 조각을 많이 읽습니다.
- 그 조각들을 참조 유전체의 알맞은 위치에 붙입니다.
- 같은 위치에서 여러 read가 어떤 염기를 가리키는지 확인합니다.
- 참조 유전체와 다르게 보이는 위치를 후보로 잡습니다.
- 품질이 낮거나 의심스러운 후보는 걸러냅니다.
- 최종 변이 목록을 VCF 같은 파일로 저장합니다.
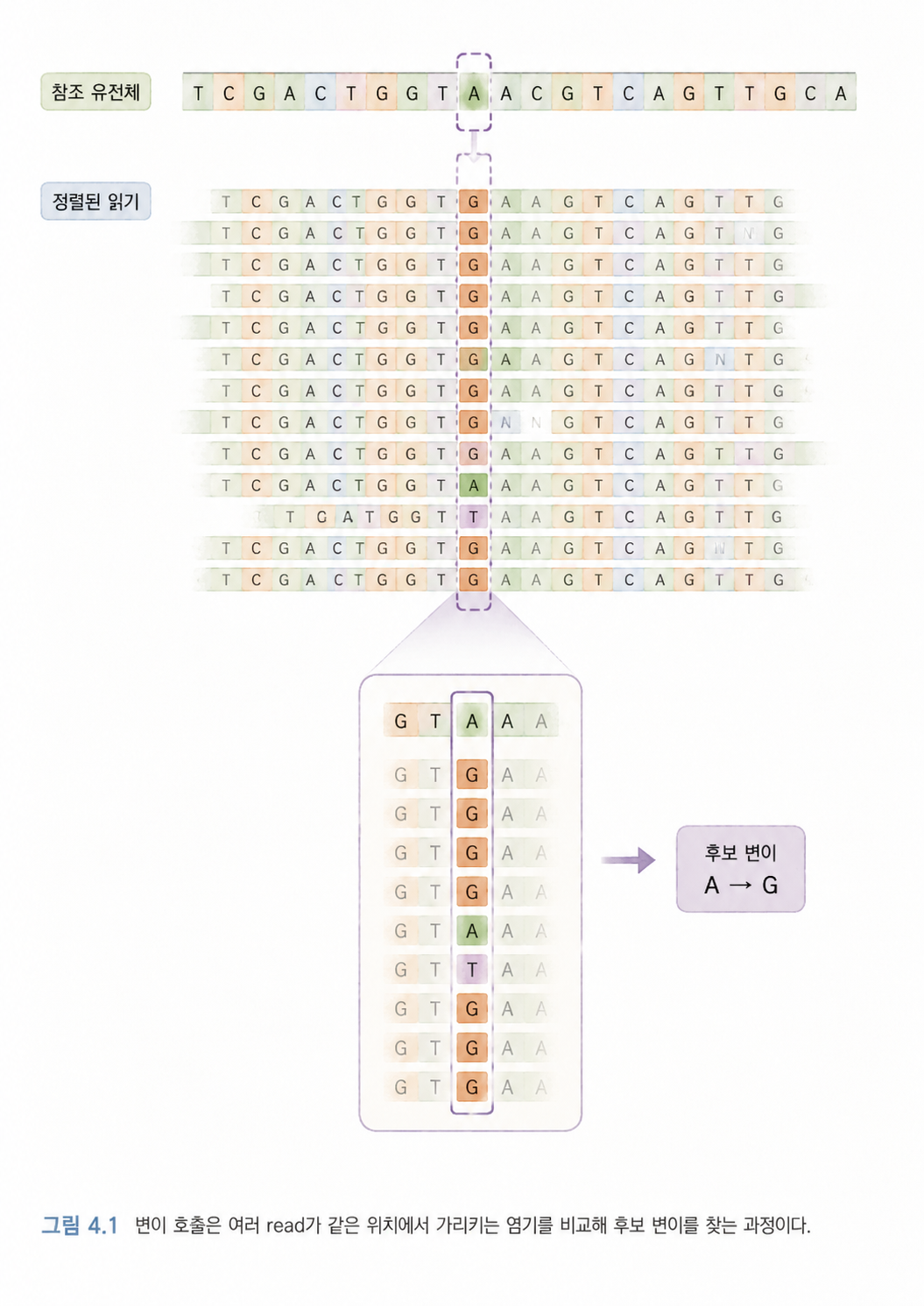
여기서 중요한 점은, 변이 찾기는 한 번에 “정답!” 하고 나오는 과정이 아니라는 것입니다. 시퀀싱 오류, 정렬 오류, 샘플 오염, 반복 서열, 낮은 품질 같은 문제가 섞일 수 있습니다. 그래서 변이 호출 도구는 확률과 품질 점수를 사용해 “이 위치는 진짜 변이일 가능성이 높다” 또는 “이 위치는 믿기 어렵다”를 판단합니다.
3. VCF는 변이 목록을 담는 표준 양식입니다
VCF(Variant Call Format)는 변이 정보를 저장하는 표준 파일 형식입니다. 아주 단순하게 말하면 DNA에서 발견한 차이점 목록표입니다.
예를 들어 어떤 염색체의 12345번째 위치에서 표준 유전체에는 C가 있는데, 어떤 사람에게는 T가 발견되었다고 해보겠습니다. 그러면 VCF에는 대략 다음과 같은 정보가 들어갑니다.
| 항목 | 뜻 | 쉬운 설명 |
|---|---|---|
| CHROM | 염색체 | 어느 염색체에서 발견되었는지입니다. |
| POS | 위치 | 그 염색체의 몇 번째 자리인지입니다. |
| REF | 기준 염기 | 참조 유전체에 적힌 글자입니다. |
| ALT | 대체 염기 | 분석 대상 샘플에서 발견된 다른 글자입니다. |
| QUAL | 품질 | 이 변이 판단을 얼마나 믿을 수 있는지입니다. |
| FILTER | 필터 결과 | 기준을 통과했는지, 문제가 있는지입니다. |
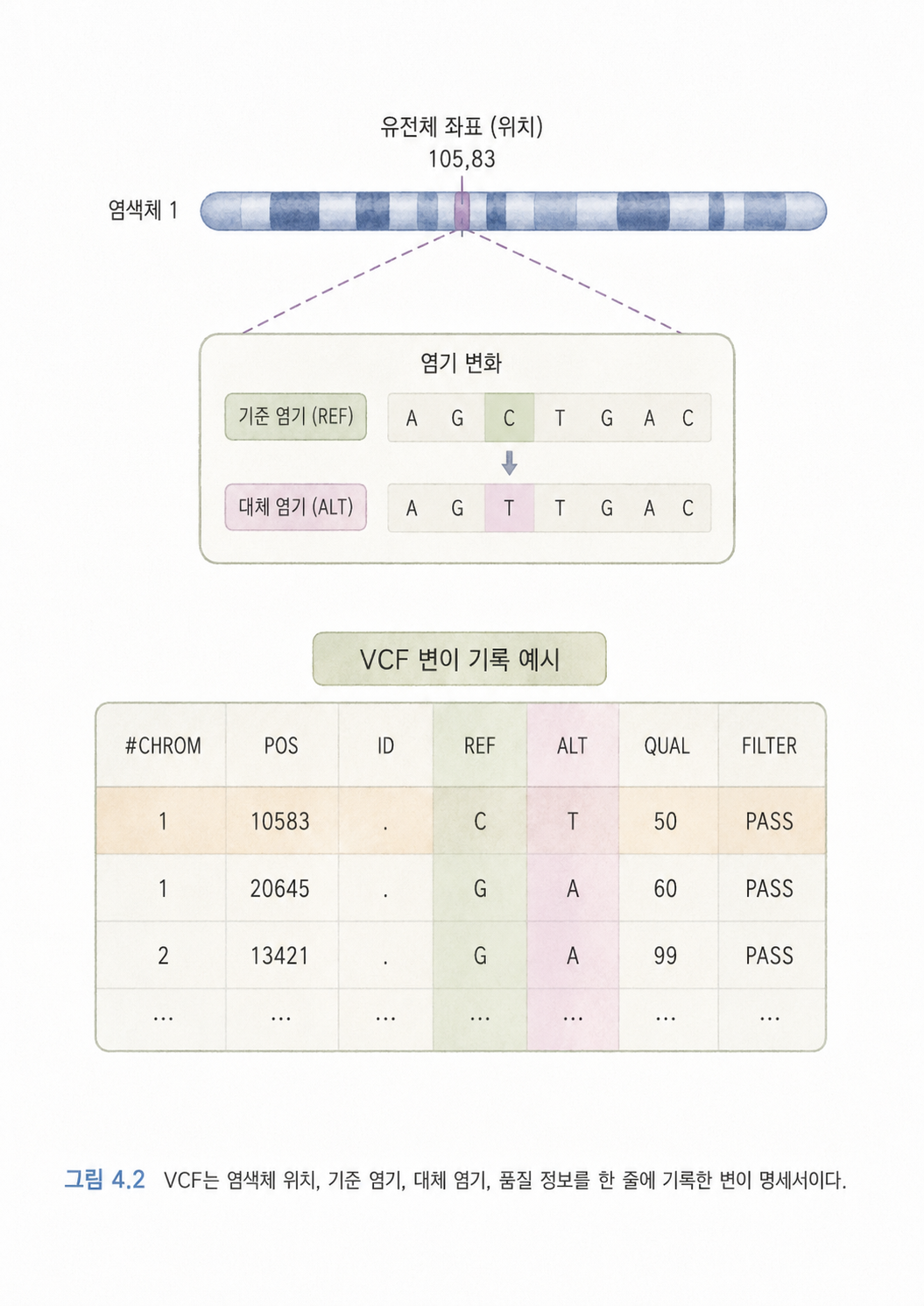
처음에는 VCF를 “컴퓨터가 읽는 유전변이 명세서”라고 생각하면 됩니다. 사람이 읽기에는 딱딱하지만, 연구 도구들이 서로 변이 정보를 주고받기에는 편리합니다.
2장에서 SNV, SNP, INDEL, 구조적 변이 같은 변이 종류를 이미 다루었습니다. 자세한 설명은 2장 선수지식의 “유전적 변이” 부분을 참고하시면 됩니다. 여기서는 VCF가 그런 변이들을 표준화해서 기록하는 파일이라고 이해하면 충분합니다.
4. 참조 유전체는 “정답지”가 아니라 “비교용 지도”입니다
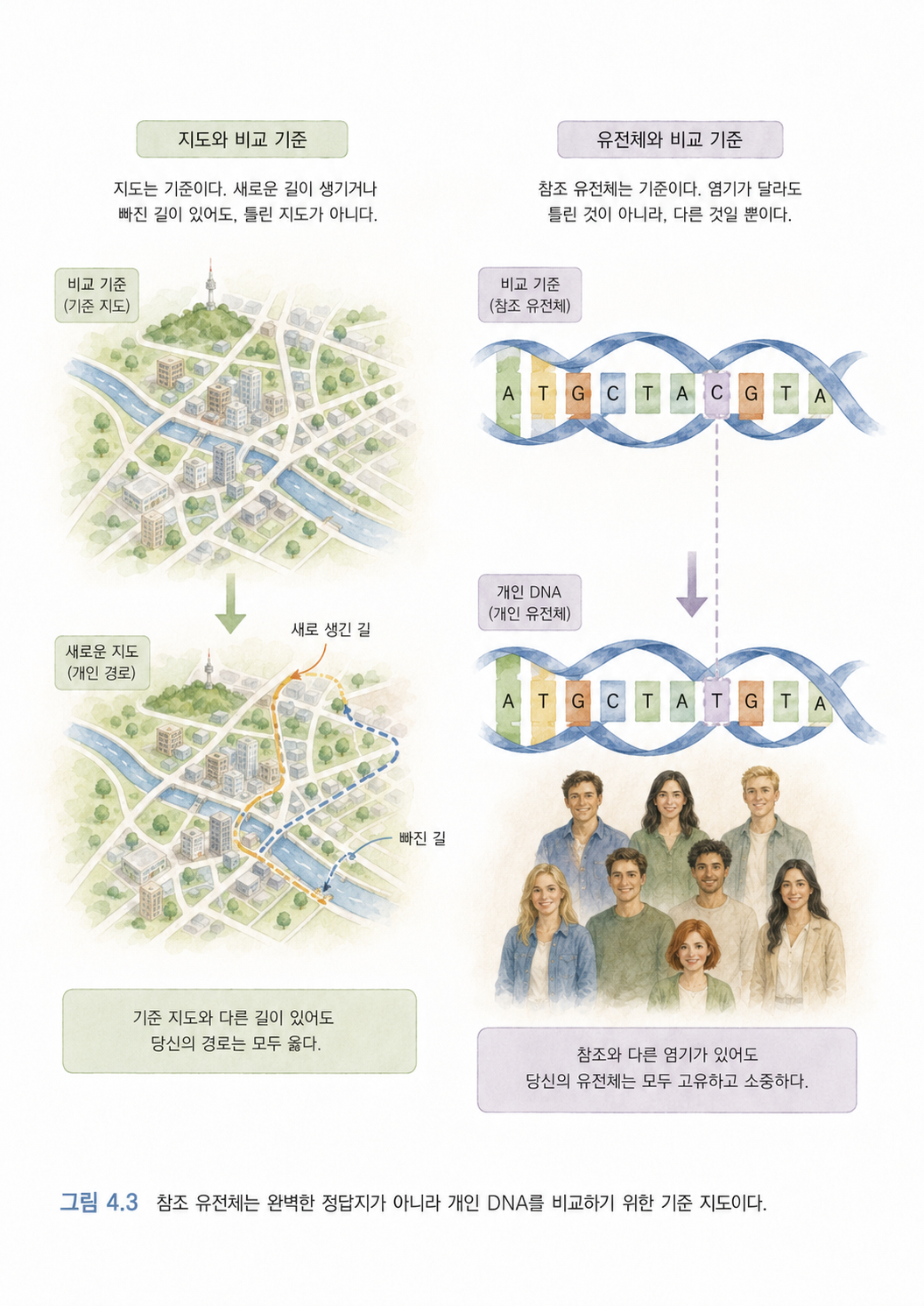
변이 분석에서 참조 유전체(Reference Genome)는 매우 중요합니다. 하지만 참조 유전체를 “완벽한 인간 DNA 정답지”라고 생각하면 안 됩니다. 참조 유전체는 특정 종을 대표하도록 만든 비교용 지도에 가깝습니다.
지도에 비유해보겠습니다. 서울 지도가 있다고 해서 서울의 모든 골목, 모든 공사 상황, 모든 가게 변화를 완벽히 반영하는 것은 아닙니다. 그래도 우리는 지도를 기준으로 “이 건물은 지도에 없네”, “여기 길이 바뀌었네”라고 말할 수 있습니다.
유전체 분석도 마찬가지입니다. 개인 DNA를 참조 유전체에 맞춰보며 차이를 찾습니다. 이때 차이는 개인의 유전적 특징일 수도 있고, 질병과 관련된 변이일 수도 있고, 분석 과정에서 생긴 오류일 수도 있습니다.
그래서 4장을 읽을 때는 다음 문장을 기억하면 좋습니다.
변이란 “절대적으로 틀린 DNA”가 아니라 “비교 기준과 다른 DNA 위치”입니다.
5. Phasing은 두 벌의 염색체 중 어느 쪽에 변이가 있는지 맞추는 일입니다
사람은 대부분의 염색체를 두 벌씩 가지고 있습니다. 하나는 어머니에게서, 하나는 아버지에게서 물려받습니다. 그래서 같은 유전자 위치도 두 복사본이 존재할 수 있습니다.
Phasing은 여러 변이가 있을 때, 이 변이들이 같은 염색체 복사본 위에 있는지, 아니면 서로 다른 복사본 위에 있는지를 추정하는 일입니다.
쉬운 예를 들어보겠습니다.
어떤 유전자 근처에 변이 2개가 있다고 해보겠습니다.
- 위치 1: A 대신 G
- 위치 2: C 대신 T
이 두 변이가 같은 염색체 위에 함께 있을 수도 있고, 하나는 어머니 쪽 염색체에, 하나는 아버지 쪽 염색체에 따로 있을 수도 있습니다. 겉으로 보기에는 변이가 두 개 있다는 사실은 같지만, 실제 생물학적 의미는 달라질 수 있습니다.
비유하자면, 책이 두 권 있다고 생각하면 됩니다. 하나는 어머니에게서 받은 책, 하나는 아버지에게서 받은 책입니다. 책 안에 오타가 두 개 발견되었는데, 두 오타가 같은 책에 있는지, 아니면 서로 다른 책에 하나씩 있는지 확인하는 일이 Phasing입니다.
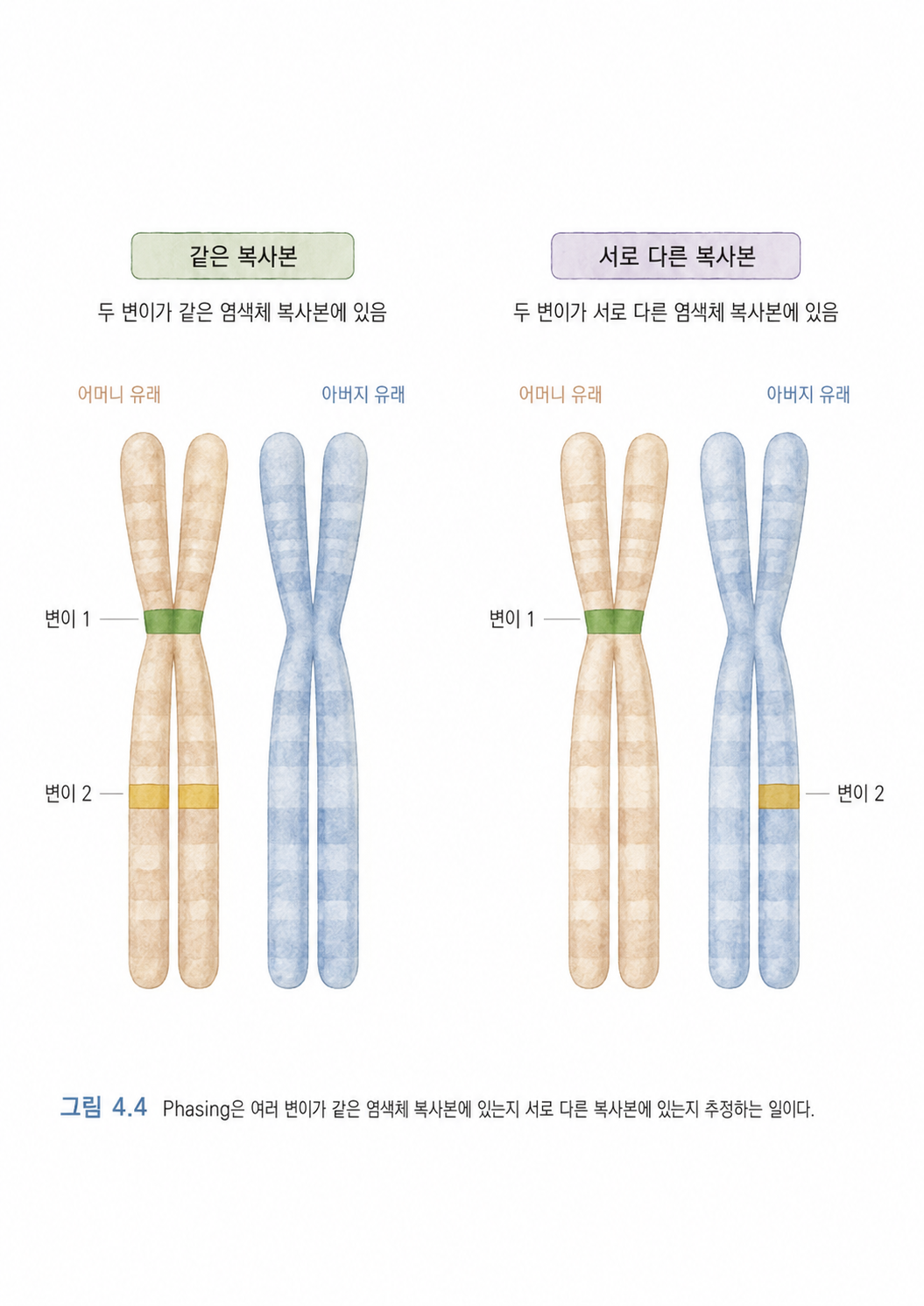
Phasing이 중요한 이유는 유전질환 해석에서 특히 큽니다. 어떤 질병은 두 복사본이 모두 망가져야 발생합니다. 이때 변이 두 개가 같은 복사본에 몰려 있는지, 양쪽 복사본에 하나씩 있는지에 따라 질병 가능성 해석이 달라질 수 있습니다.
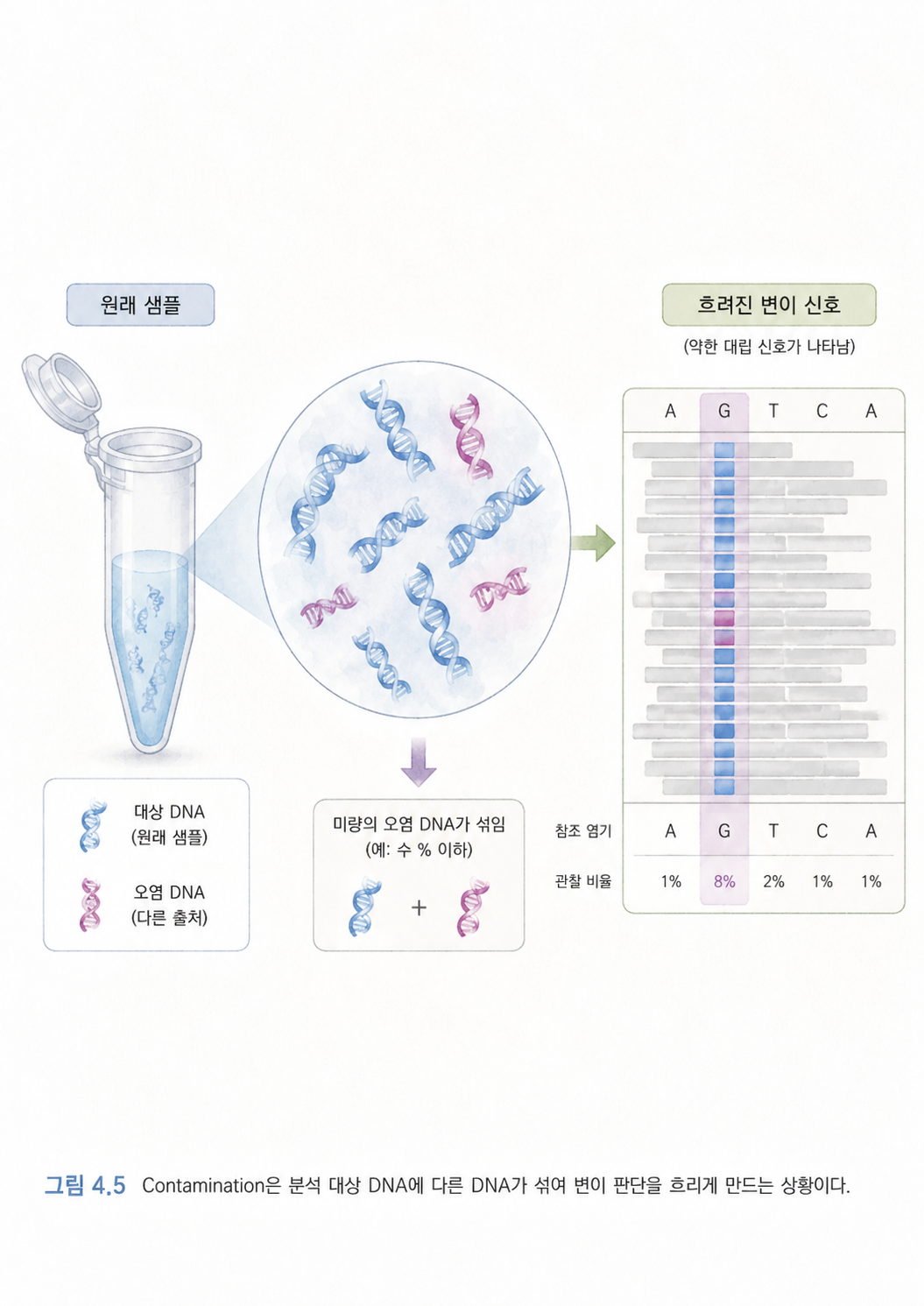
6. Contamination은 샘플에 다른 DNA가 섞인 상황입니다
Contamination은 오염이라는 뜻입니다. 유전체 분석에서 오염은 분석하려는 샘플에 다른 사람이나 다른 생물의 DNA가 섞인 상황을 말합니다.
예를 들어 컵에 물을 담아 분석하려는데, 누군가 주스를 몇 방울 떨어뜨렸다고 해보겠습니다. 그럼 컵 안 액체는 더 이상 순수한 물이 아닙니다. 마찬가지로 어떤 사람의 DNA를 분석하려는데 다른 사람의 DNA가 조금 섞이면, 컴퓨터는 이상한 결과를 낼 수 있습니다.
오염은 여러 단계에서 생길 수 있습니다.
- 샘플을 채취할 때 다른 물질이 섞일 수 있습니다.
- 실험실에서 다른 샘플과 교차 오염될 수 있습니다.
- 시약이나 장비에 남아 있던 DNA가 섞일 수 있습니다.
- 여러 샘플을 동시에 처리하다가 바코드나 인덱스 문제가 생길 수 있습니다.
오염이 생기면 변이 호출 결과가 왜곡될 수 있습니다. 실제로는 없는 변이가 있는 것처럼 보이거나, 실제 변이가 흐릿하게 보일 수 있습니다. 그래서 유전체 분석에서는 샘플 품질 관리가 중요합니다.
7. 하디-바인베르크 평형은 “변화가 없다면 비율이 이렇게 유지될 것이다”라는 기준선입니다
4장 중반부터는 개인 DNA 분석을 넘어 집단유전학으로 넘어갑니다. 여기서 하디-바인베르크 평형(Hardy-Weinberg Equilibrium)이 나옵니다.
이 개념은 처음 보면 수식 때문에 겁이 날 수 있습니다. 하지만 핵심은 단순합니다.
어떤 집단에서 특별한 힘이 작용하지 않는다면, 대립유전자의 비율은 세대가 지나도 일정하게 유지될 것이라고 보는 기준 모델입니다.
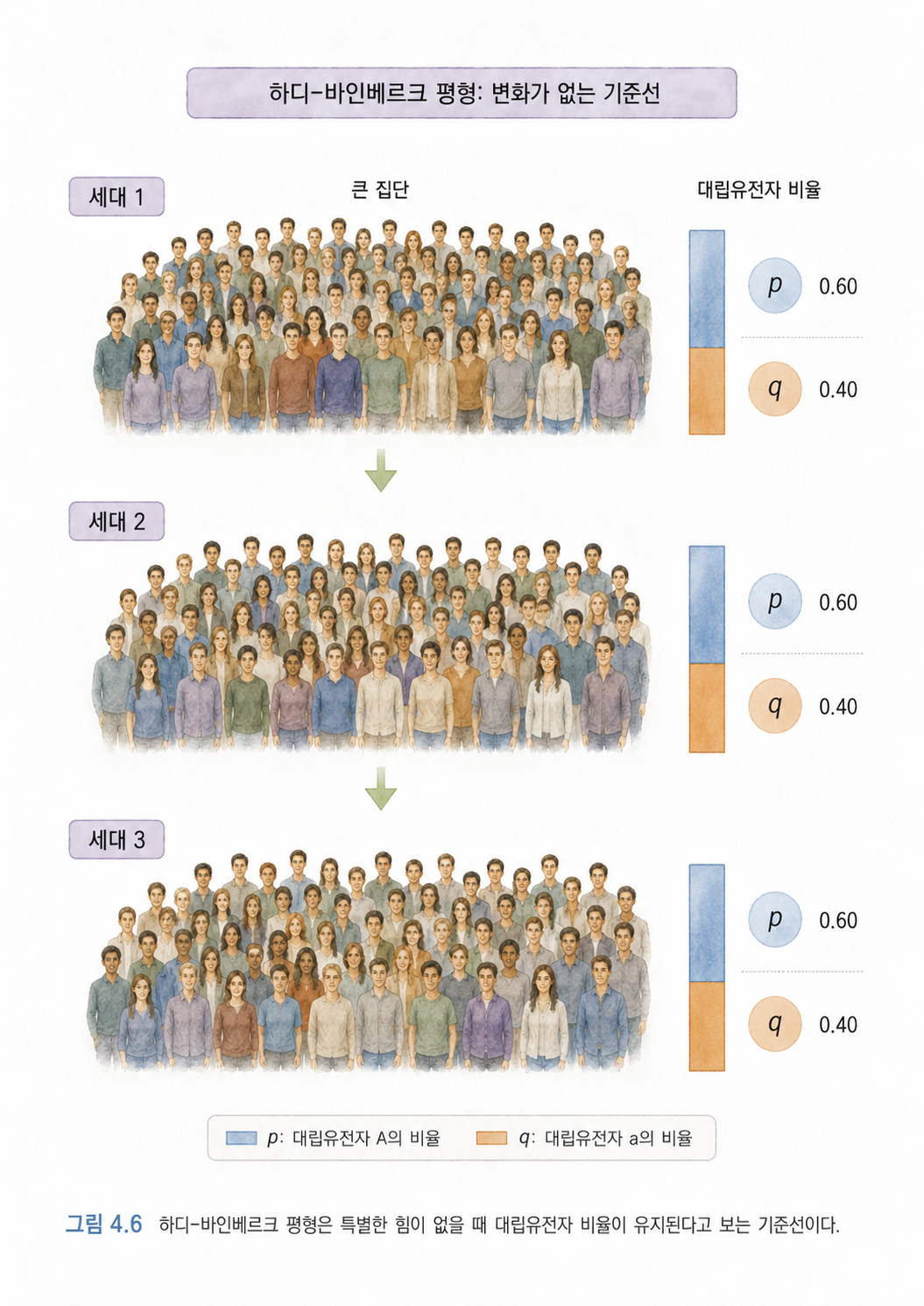
여기서 특별한 힘이란 자연선택, 돌연변이, 이주, 유전적 부동, 비무작위 교배 같은 것을 말합니다.

동전 던지기를 생각해보겠습니다. 동전이 공정하다면 앞면과 뒷면은 대략 절반씩 나올 것이라고 기대합니다. 그런데 실제로 10번만 던지면 앞면이 8번 나올 수도 있습니다. 10,000번 던지면 대체로 50:50에 가까워집니다.
집단유전학에서도 비슷한 생각을 합니다. 큰 집단에서는 유전자 비율이 비교적 안정적으로 유지될 수 있습니다. 반면 작은 집단에서는 우연만으로도 어떤 대립유전자가 확 늘거나 사라질 수 있습니다.
하디-바인베르크 평형은 현실이 반드시 그렇다는 뜻이 아닙니다. 오히려 현실이 이 기준에서 벗어난다면, “무언가 변화시키는 힘이 작용하고 있구나”라고 의심할 수 있게 해주는 기준선입니다.
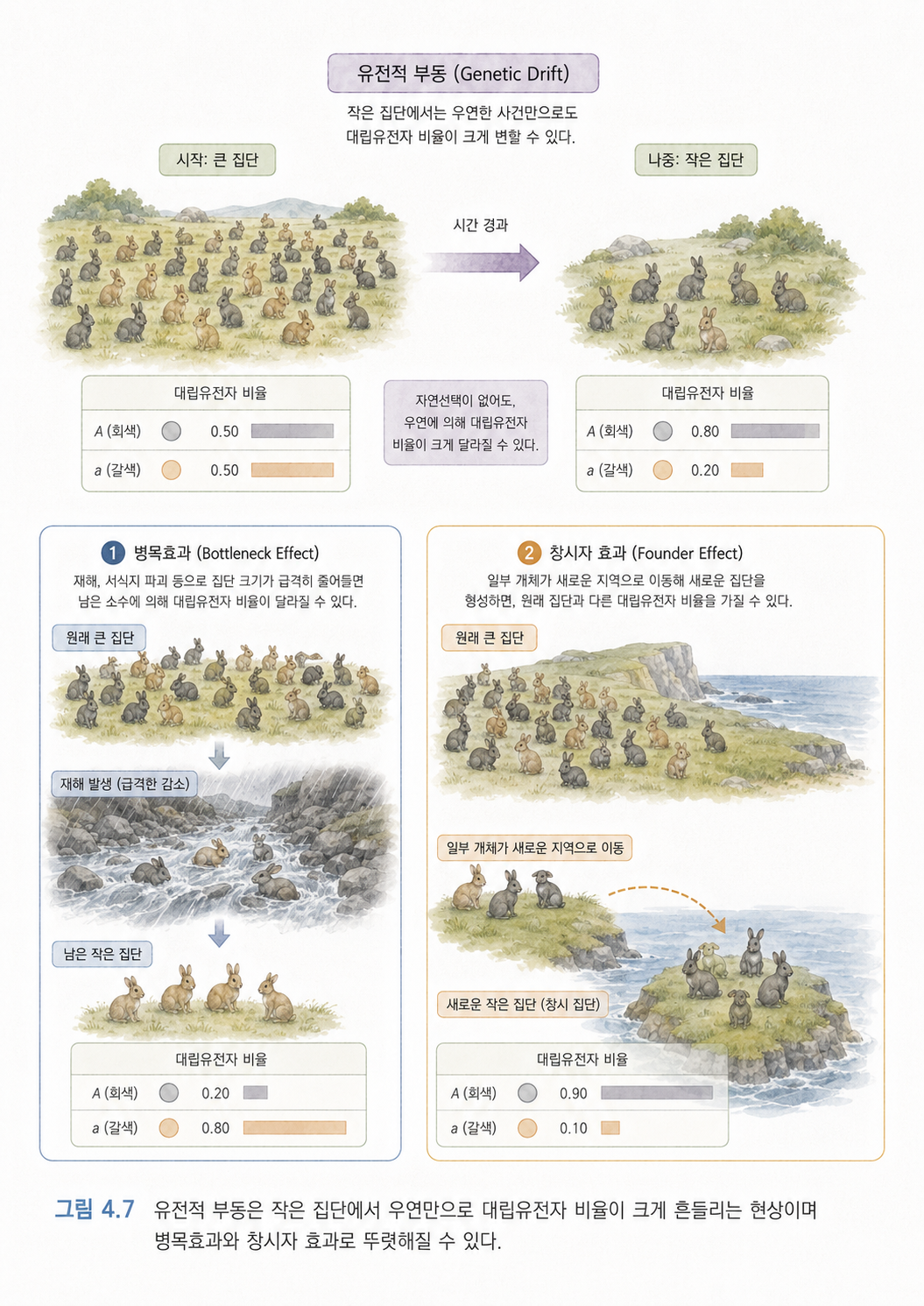
8. 유전적 부동은 작은 집단에서 우연히 유전자 비율이 바뀌는 현상입니다
유전적 부동(Genetic Drift)은 자연선택처럼 “좋은 형질이 살아남는다”는 이야기와 다릅니다. 유전적 부동은 그냥 우연 때문에 대립유전자 비율이 바뀌는 현상입니다.
작은 마을에 빨간 구슬과 파란 구슬이 섞인 주머니가 있다고 해보겠습니다. 다음 세대는 이 주머니에서 뽑힌 구슬들로 만들어집니다. 주머니가 엄청 크고 많이 뽑으면 빨강과 파랑의 비율이 원래와 비슷하게 유지됩니다. 하지만 주머니가 작고 몇 개만 뽑으면 우연히 빨간 구슬만 많이 뽑힐 수 있습니다. 그러면 다음 세대에서는 빨간 구슬 비율이 확 늘어납니다.
생물 집단에서도 비슷한 일이 생깁니다. 특히 집단 크기가 작을 때, 어떤 변이가 생존에 유리하지 않아도 우연히 퍼질 수 있고, 반대로 별로 나쁘지 않은 변이가 우연히 사라질 수도 있습니다.
이 개념은 진화를 이해할 때 중요합니다. 진화는 항상 “강한 자가 살아남는다”처럼 단순하지 않습니다. 때로는 우연이 매우 큰 역할을 합니다.
9. 진화는 “생물 개체가 갑자기 변신하는 것”이 아니라 “집단의 유전자 비율이 바뀌는 것”입니다
일상에서 진화라는 말을 들으면 포켓몬처럼 한 개체가 갑자기 다른 모습으로 변하는 장면을 떠올리기 쉽습니다. 하지만 생물학에서 진화는 그런 뜻이 아닙니다.
생물학에서 진화는 보통 세대를 거치며 집단 안의 유전적 구성이 바뀌는 것을 말합니다.

예를 들어 어떤 곤충 집단에 살충제 저항성 변이가 아주 조금 있었다고 해보겠습니다. 살충제를 뿌리기 전에는 이 변이가 별로 중요하지 않았습니다. 그런데 살충제를 뿌리기 시작하면 저항성 변이를 가진 곤충이 더 잘 살아남습니다. 시간이 지나면 저항성 변이의 비율이 집단 안에서 높아집니다. 이것이 진화입니다.
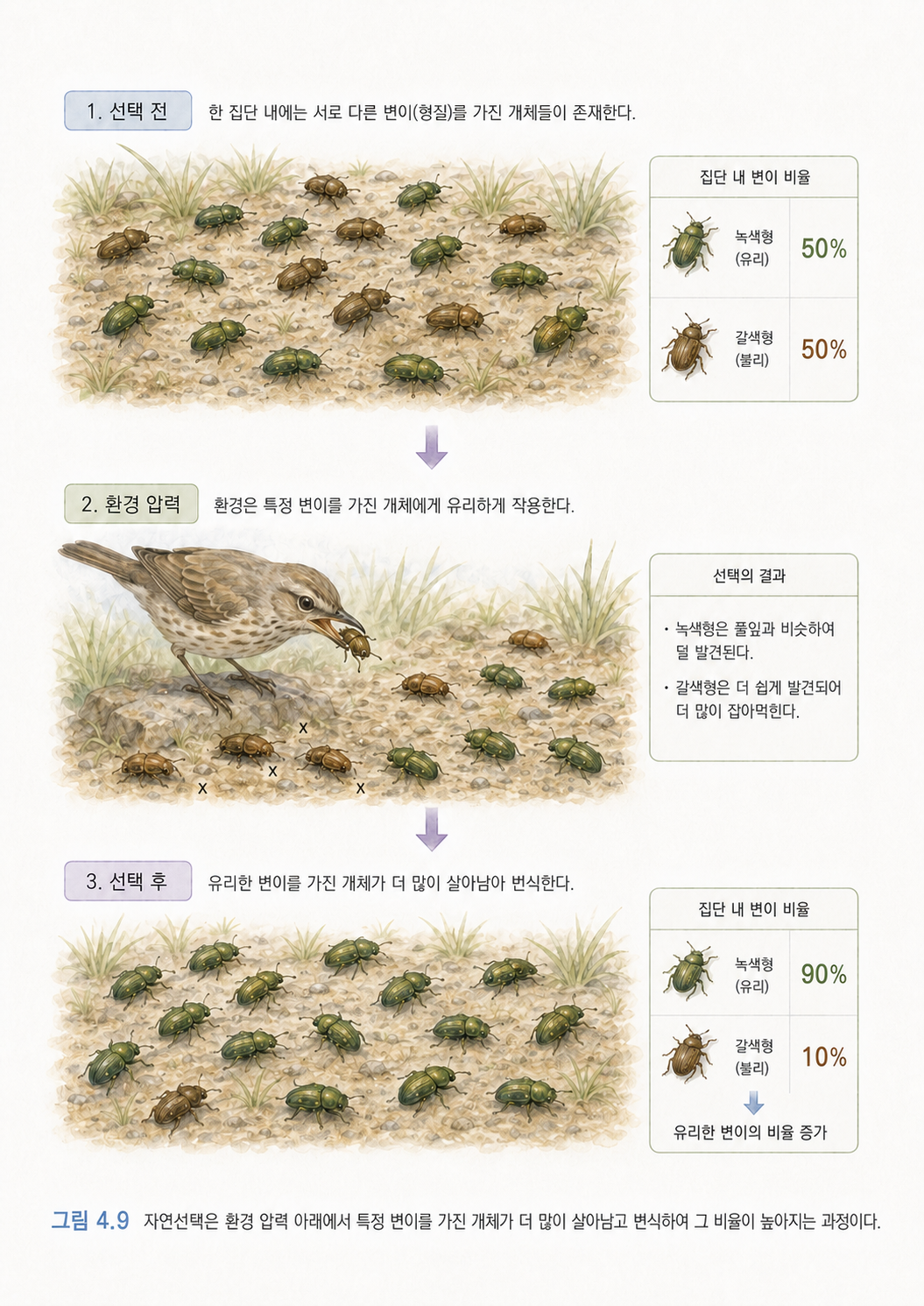
진화의 주요 힘은 다음 세 가지로 이해하면 좋습니다.
| 힘 | 쉬운 설명 | 예시 |
|---|---|---|
| 무작위 돌연변이 | DNA에 새로운 차이가 생깁니다. | 복제 과정에서 염기가 바뀝니다. |
| 자연선택 | 환경에 유리한 변이가 더 잘 남습니다. | 항생제 내성 세균이 살아남습니다. |
| 유전적 부동 | 우연 때문에 변이 비율이 바뀝니다. | 작은 집단에서 특정 변이가 우연히 퍼집니다. |
4장에서는 이 개념들이 변이 데이터 분석과 연결됩니다. DNA 서열을 비교하면 생물들이 얼마나 가까운 친척인지, 병원체가 어떻게 퍼졌는지, 오래된 생물이 현대 생물과 어떤 관계인지 추정할 수 있습니다.
10. 다중서열정렬은 여러 DNA 문장을 줄 맞춰 비교하는 일입니다
다중서열정렬(Multiple Sequence Alignment)은 여러 DNA 또는 단백질 서열을 나란히 놓고 비슷한 위치끼리 맞추는 일입니다.
예를 들어 다음과 같은 서열들이 있다고 해보겠습니다.
표본 A: ATGCAATTA
표본 B: ATGCAATCA
표본 C: ATGTAATCA
이 서열들을 잘 맞춰보면 어느 위치가 같고, 어느 위치가 다른지 볼 수 있습니다. 차이가 적은 서열끼리는 더 가까운 관계일 가능성이 높습니다. 차이가 많으면 더 오래전에 갈라졌을 가능성이 높습니다.
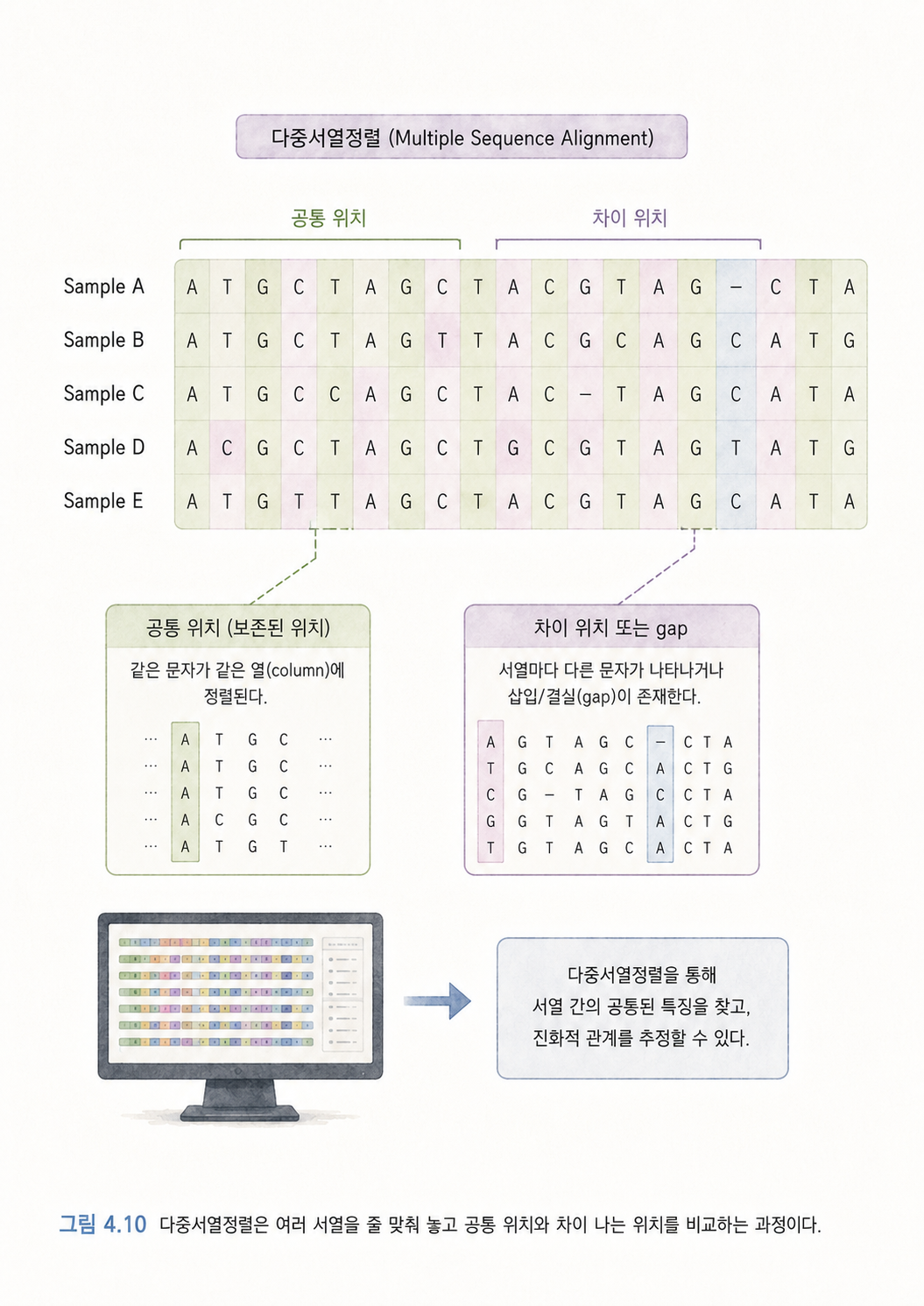

이런 방식은 감염병 추적에서 특히 중요합니다. 바이러스는 복제되면서 조금씩 변이를 쌓습니다. 서로 다른 환자에게서 나온 바이러스 서열을 비교하면, 어떤 바이러스가 어느 것과 가까운지, 전파가 어떤 방향으로 일어났을 가능성이 있는지 추정할 수 있습니다.
물론 서열이 비슷하다고 해서 모든 관계가 100% 확정되는 것은 아닙니다. 하지만 다중서열정렬과 계통수는 생명정보학에서 진화적 관계를 추정하는 핵심 도구입니다.
11. 계통수는 생물이나 바이러스의 친척 관계를 나무처럼 그린 것입니다
계통수(Phylogenetic Tree)는 생물, 유전자, 바이러스 표본 사이의 관계를 나무 모양으로 표현한 그림입니다.
나무의 가지가 가까이 붙어 있으면 비교적 가까운 관계라고 해석합니다. 멀리 떨어져 있으면 더 오래전에 갈라졌다고 봅니다. 사람의 족보와 비슷하지만, 개인 가족관계보다는 생물종, 유전자, 바이러스 서열의 진화적 관계를 나타낸다는 점이 다릅니다.
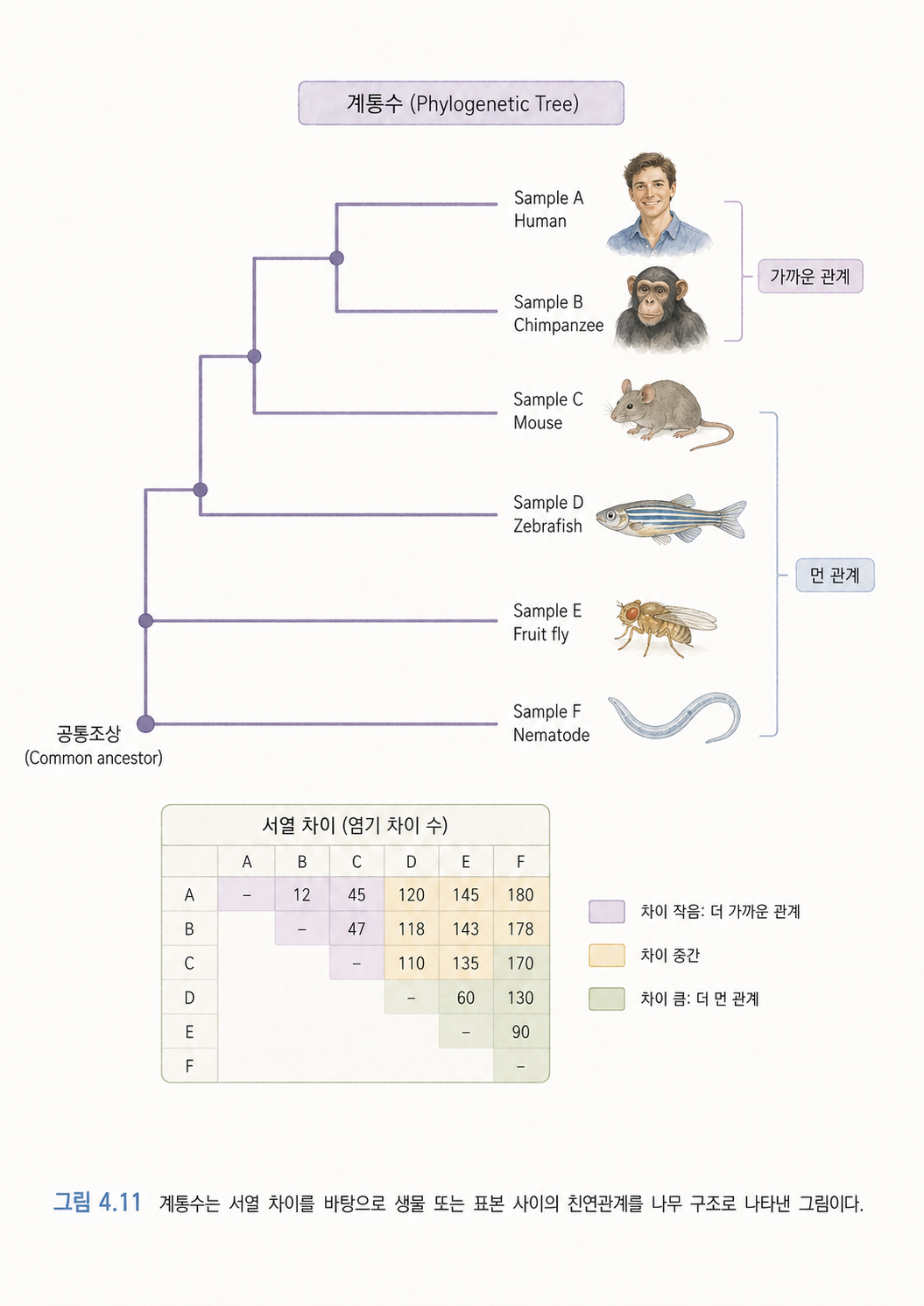
예를 들어 COVID-19 같은 감염병에서는 여러 나라, 여러 환자에게서 얻은 바이러스 서열을 비교해 변이 계통을 추적할 수 있습니다. 이때 계통수는 감염병이 어떻게 퍼졌는지 이해하는 데 도움을 줍니다.
고유전학에서도 계통수는 중요합니다. 오래된 뼈나 유해에서 추출한 DNA를 현대인의 DNA와 비교하면, 고대 인류 집단과 현대 인류 집단 사이의 관계를 추정할 수 있습니다.
12. 고유전학은 오래된 DNA로 과거를 읽는 분야입니다
고유전학은 고대 생물이나 고대 인류의 DNA를 분석하는 분야입니다. 오래된 뼈, 치아, 미라, 화석 같은 것에서 DNA를 추출해 과거 생물의 유전 정보를 연구합니다.
하지만 오래된 DNA는 상태가 좋지 않은 경우가 많습니다. 시간이 지나면 DNA가 잘게 끊어지고, 화학적으로 손상되고, 현대인의 DNA나 미생물 DNA가 섞일 수도 있습니다. 그래서 고유전학에서는 contamination 문제와 손상 패턴 해석이 매우 중요합니다.
고유전학은 단순히 “옛날 사람의 DNA가 궁금하다”에서 끝나지 않습니다. 인류가 어떻게 이동했는지, 어떤 집단끼리 섞였는지, 멸종한 생물과 현생 생물이 어떤 관계인지, 과거 병원체가 어떻게 퍼졌는지 같은 질문에 답할 수 있습니다.

본편 진입 전 보강: 하디-바인베르크 평형을 아주 작은 숫자로 계산해보기
하디-바인베르크 평형은 “특별한 힘이 작용하지 않는다면 유전자형 비율이 이렇게 기대된다”는 기준선입니다. 여기서 자주 나오는 기호는 p와 q입니다.
p: A 대립유전자의 빈도q: a 대립유전자의 빈도p + q = 1

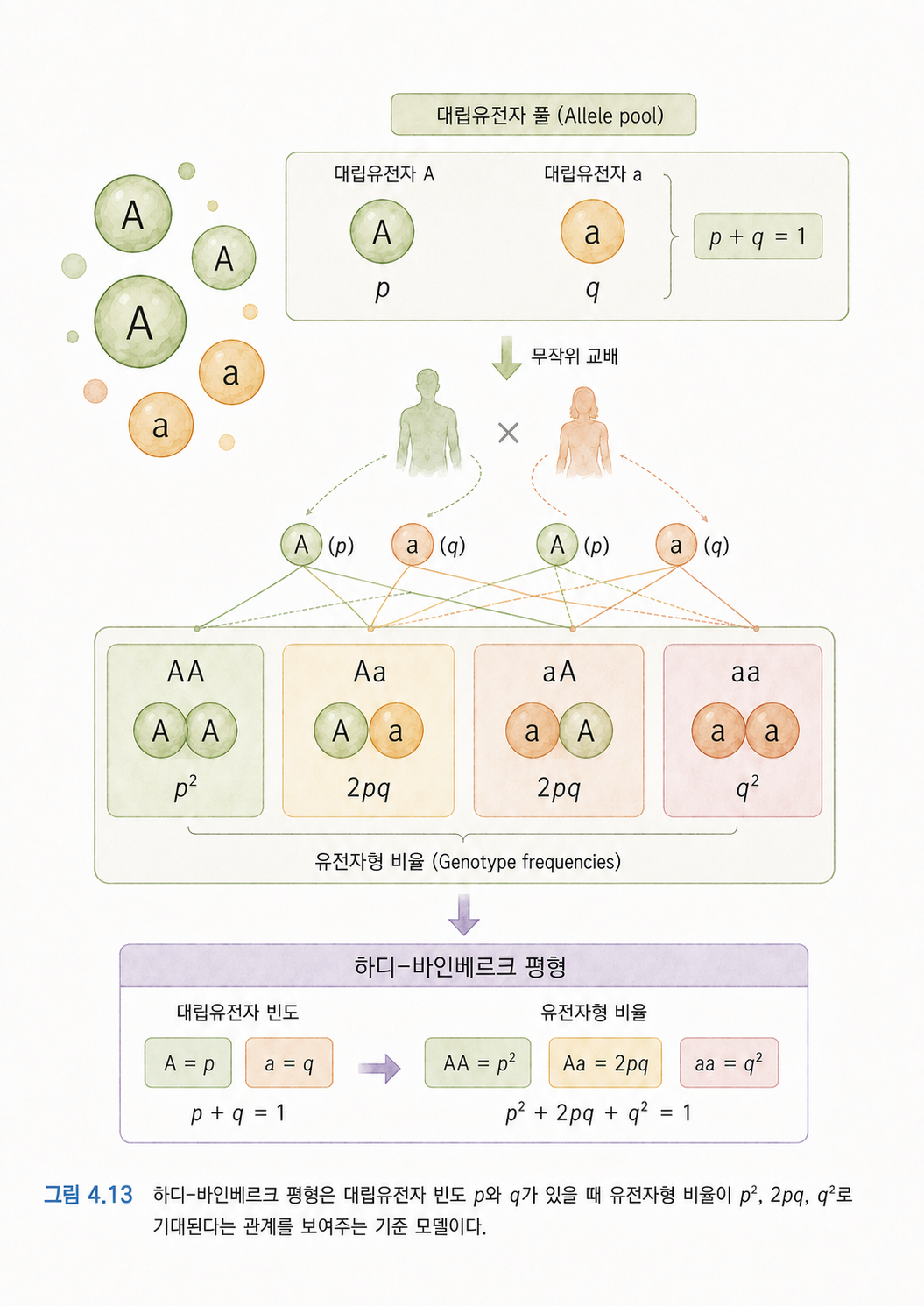
예를 들어 A의 빈도 p가 0.7이고, a의 빈도 q가 0.3이라고 해보겠습니다. 하디-바인베르크 평형에서는 유전자형 비율을 대략 이렇게 기대합니다.
AA = p² = 0.7 × 0.7 = 0.49
Aa = 2pq = 2 × 0.7 × 0.3 = 0.42
aa = q² = 0.3 × 0.3 = 0.09
이 값들은 “반드시 현실이 이렇게 된다”는 뜻이 아닙니다. 현실 자료가 이 기준에서 크게 벗어나면, 선택, 집단 구조, 근친교배, 표본 문제, 유전형 판정 오류 같은 이유를 의심할 수 있습니다.
본편 진입 전 보강: 2N은 이배체 집단의 전체 대립유전자 수입니다
사람처럼 대부분의 염색체를 두 벌씩 가진 생물을 이배체라고 합니다. 개체가 N명이라면 한 위치에 대한 대립유전자 자리는 보통 2N개입니다.
예를 들어 5명의 이배체 개체를 조사하면 전체 대립유전자 수는 다음과 같습니다.
2N = 2 × 5 = 10개
Wright-Fisher 모델에서는 다음 세대의 대립유전자가 이 전체 풀에서 무작위로 뽑힌다고 단순화해서 생각합니다. 그래서 작은 집단에서는 우연만으로도 대립유전자 빈도가 크게 흔들릴 수 있습니다. 이것이 유전적 부동입니다.
본편 진입 전 보강: VCF 한 줄을 실제 문장으로 바꿔 읽기
VCF는 변이 정보를 표처럼 담습니다. 입문 단계에서는 최소한 CHROM, POS, REF, ALT만 읽어도 좋습니다.
CHROM POS REF ALT
chr1 100 A G
이 한 줄은 “1번 염색체 100번 위치에서 기준 염기 A 대신 G가 관찰되었다”라는 뜻입니다. VCF를 볼 때는 숫자와 문자를 생물학 문장으로 바꿔 읽는 연습이 중요합니다.
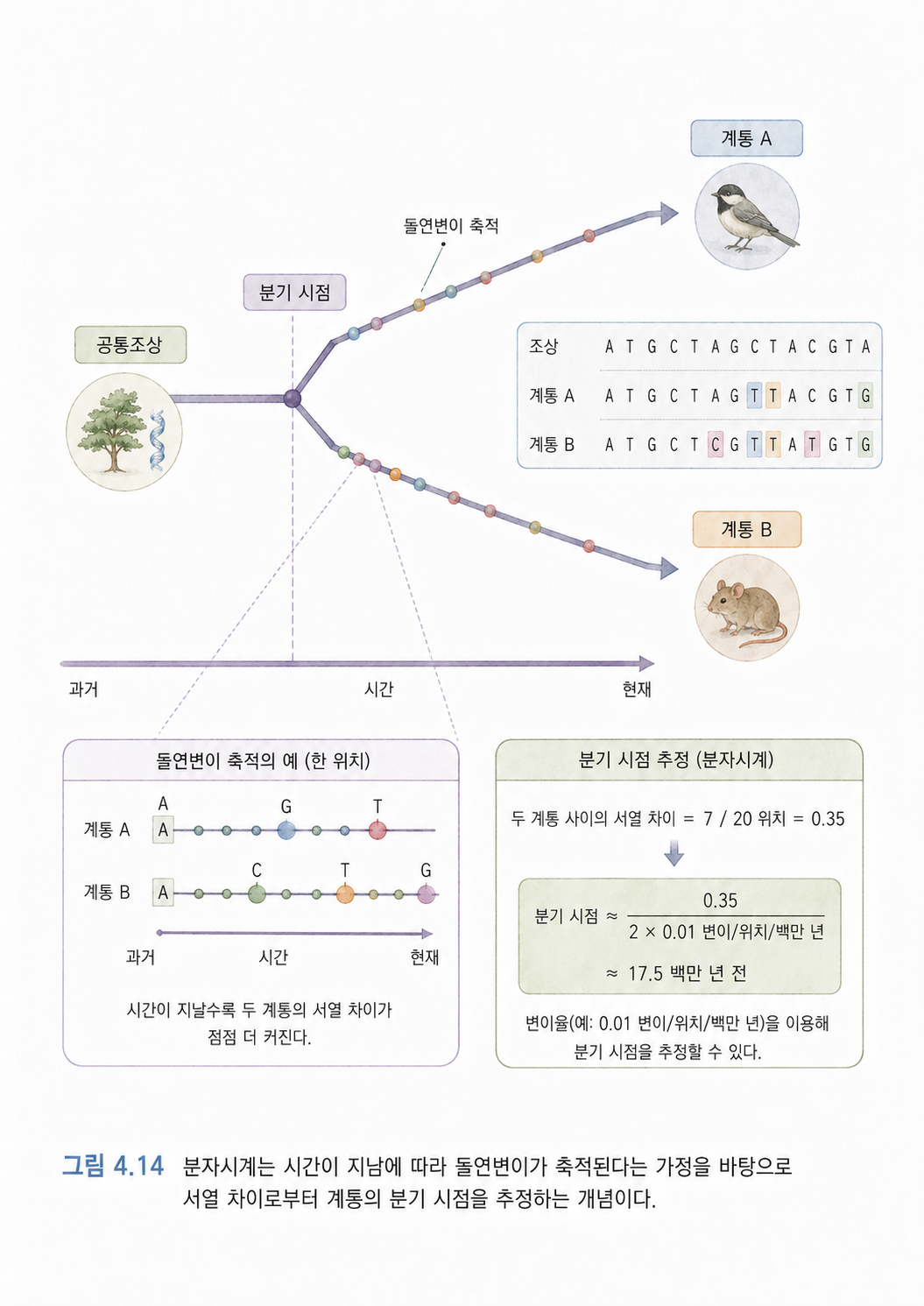
본편 진입 전 보강: 분자시계는 서열 차이를 시간 감각으로 바꿔보는 모델입니다
분자시계(Molecular Clock)는 시간이 지나며 돌연변이가 어느 정도 누적된다고 보고, 두 계통 사이의 서열 차이로부터 분기 시점을 추정하는 생각입니다. 예를 들어 두 계통의 서열 차이가 많다면, 더 오래전에 갈라졌을 가능성을 생각해볼 수 있습니다.
다만 실제 변이율은 종, 유전자, 세대 시간, 환경, 선택 압력에 따라 달라질 수 있습니다. 그래서 분자시계는 절대적인 시계라기보다, 서열 차이를 진화 시간과 연결해 해석하는 추정 모델이라고 보는 편이 안전합니다.
13. 4챕터 진입 전 핵심 정리
| 선수지식 | 아주 쉬운 설명 | 4챕터에서 필요한 이유 |
|---|---|---|
| 변이 호출 | 참조 유전체와 다른 위치를 찾는 과정입니다. | 개인 유전체 분석의 핵심 단계입니다. |
| VCF | 변이 정보를 담는 표준 파일입니다. | 변이 결과를 읽고 공유할 때 필요합니다. |
| Phasing | 변이가 부모 쪽 염색체 중 어느 쪽에 있는지 추정합니다. | 변이 조합의 의미를 해석할 때 중요합니다. |
| 오염 | 샘플에 다른 DNA가 섞인 상황입니다. | 잘못된 변이 판단을 막기 위해 알아야 합니다. |
| 하디-바인베르크 평형 | 변화가 없다면 유전자 비율이 유지된다는 기준 모델입니다. | 진화나 집단 구조를 해석하는 기준선입니다. |
| 유전적 부동 | 우연만으로 변이 비율이 바뀌는 현상입니다. | 작은 집단의 진화를 이해하는 데 필요합니다. |
| 계통수 | 서열 차이를 바탕으로 친척 관계를 그린 나무입니다. | 병원체 추적과 진화 분석에 사용됩니다. |
| 분자시계 | 서열 차이를 시간 감각으로 바꾸어 분기 시점을 추정하는 모델입니다. | 계통 사이의 서열 차이를 진화 시간 해석과 연결할 때 필요합니다. |
| p, q, 2N | 대립유전자 빈도와 이배체 집단의 전체 대립유전자 수입니다. | HWE와 Wright-Fisher 모델의 수식 감각에 필요합니다. |
| p², 2pq, q² | HWE에서 기대되는 유전자형 비율입니다. | 관찰된 유전자형 비율이 기준에서 벗어나는지 해석하게 해줍니다. |
문제 풀이
변이와 진화
주관식 답안은 Gemini API로 채점합니다. API 키는 이 브라우저에만 저장됩니다.
-
1. [쉬움] 객관식
변이 호출(variant calling)의 의미로 가장 적절한 것은 무엇인가?
-
2. [쉬움] 객관식
VCF 파일의 역할로 가장 적절한 것은 무엇인가?
-
3. [쉬움] 객관식
Phasing의 의미로 가장 적절한 것은 무엇인가?
-
4. [쉬움] 객관식
샘플 contamination에 대한 설명으로 가장 적절한 것은 무엇인가?
-
5. [쉬움] 객관식
진화를 유전학적으로 가장 적절히 설명한 것은 무엇인가?
-
6. [보통] 객관식
하디-바인베르크 평형의 역할로 가장 적절한 것은 무엇인가?
-
7. [보통] 객관식
유전적 부동에 대한 설명으로 가장 적절한 것은 무엇인가?
-
8. [보통] 객관식
다중서열정렬의 목적에 가장 가까운 것은 무엇인가?
-
9. [보통] 객관식
계통수에 대한 설명으로 가장 적절한 것은 무엇인가?
-
10. [보통] 객관식
고유전학에 대한 설명으로 가장 적절한 것은 무엇인가?
-
11. [어려움] 객관식
“변이 찾기는 틀린 글자 찾기가 아니라 기준과 다른 글자 찾기”라는 말의 의미로 가장 적절한 것은 무엇인가?
-
12. [어려움] 객관식
다음 VCF 형식의 핵심 필드 연결로 가장 적절한 것은 무엇인가?
CHROM, POS, REF, ALT
-
13. [어려움] 객관식
Phasing이 중요한 상황으로 가장 적절한 것은 무엇인가?
-
14. [어려움] 객관식
하디-바인베르크 평형에서 벗어난 결과를 해석할 때 가장 적절한 태도는 무엇인가?
-
15. [어려움] 객관식
병원체 계통수 분석이 유용한 이유로 가장 적절한 것은 무엇인가?
-
16. [어려움] 객관식
다음 중 4챕터의 흐름을 가장 적절히 요약한 것은 무엇인가?
-
17. [보통] 객관식
VCF 한 줄
chr1 100 A G를 가장 적절히 해석한 것은 무엇인가? -
18. [보통] 객관식
계산형: 이배체 개체가 12명인 집단에서 한 위치에 대한 전체 대립유전자 수 2N은 얼마인가?
-
19. [보통] 객관식
계산형: A 대립유전자 빈도 p=0.6이라면 a 대립유전자 빈도 q는 얼마인가?
-
20. [보통] 객관식
계산형: p=0.6, q=0.4일 때 HWE에서 AA 기대 비율 p²는?
-
21. [보통] 객관식
계산형: p=0.6, q=0.4일 때 HWE에서 Aa 기대 비율 2pq는?
-
22. [보통] 객관식
계산형: p=0.6, q=0.4일 때 HWE에서 aa 기대 비율 q²는?
-
23. [보통] 객관식
유전적 부동이 특히 크게 나타나기 쉬운 상황은 무엇인가?
-
24. [보통] 객관식
Phasing의 핵심 질문으로 가장 적절한 것은 무엇인가?
-
1. [쉬움] 주관식 · Gemini 채점
VCF가 변이 분석에서 필요한 이유를 설명하라.
-
2. [보통] 주관식 · Gemini 채점
Contamination이 변이 호출 결과를 왜 왜곡할 수 있는지 설명하라.
-
3. [보통] 주관식 · Gemini 채점
하디-바인베르크 평형과 유전적 부동을 비교하라.
-
4. [어려움] 주관식 · Gemini 채점
계통수가 병원체 추적이나 고유전학에서 어떻게 활용될 수 있는지 설명하라.